http://www.joinc.co.kr/modules/moniwiki/wiki.php/Site/Network_Programing/AdvancedComm/HTTP
1 HTTP 프로토콜
1.1 Tim Berners-Lee
HTTP를 개발한 영국의 컴퓨터 엔지니어로 하이퍼텍스트를 개발했으며, URL, HTTP, HTML을 설계했다. HTTP와 HTML, 하이퍼텍스트의 영향이 워낙에 강력하고 광범위해서 인터넷의 아버지라고 부른다.
1.2 HTTP에 대하여
HTTP(Hypertext Transfer Protocol)는 인터넷상에서 데이터를 주고 받기 위한 서버/클라이언트 모델을 따르는 프로토콜 이다. 애플리케이션 레벨의 프로토콜로 TCP/IP위에서 작동한다.
가장 성공적인 인터넷 프로토콜이다. HTTP가 없었다면 인터넷은 지금과는 전혀 다른 모습이였을거다.
HTTP는 어떤 종류의 데이터든지 전송할 수 있도록 설계돼 있다. 인터넷상에서 흔히 볼수 있는 HTML로 작성된 문서는 HTTP로 보낼 수 있는 데이터의 한 종류일 뿐이다. 이미지, 동영상, 오디오, 텍스트 문서들 아무튼 종류를 가리지 않는다.
Transfer라는 해석 그대로 데이터를 전송하겠다라는 의미로 앞에 Hypertext[1]가 붙은 이유는 하이퍼텍스트 기반으로 데이터를 전송하겠다는. 간단히 말해서 링크기반으로 데이터에 접속하겠다는 의미가 되겠다.
1.3 작동 방식
HTTP는 서버/클라이언트 모델을 따른다. 클라이언트에서 요청(request)를 보내면 서버는 요청을 처리해서 응답(response)한다.
- 클라이언트 : 서버에 요청하는 클라이언트 소프트웨어가 설치된 컴퓨터. chrom, firefox, ie등의 클라이언트 소프트웨어를 이용한다. 클라이언트는 URI를 이용해서 서버에 접속하고, 데이터를 요청할 수 있다.
- 서버 : 클라이언트의 요청을 받아서, 요청을 해석하고 응답을 하는 소프트웨어가 설치된 컴퓨터. Apache, nginx, IIS, lighttpd 등이 서버 소프트웨어다.
1.4 Connectless & Stateless
HTTP는 Connectless 방식으로 작동한다[2]. 서버에 연결하고, 요청해서 응답을 받으면 연결을 끊어버린다. 기본적으로는 자원 하나에 대해서 하나의 연결을 만든다. 이런 작동방식은 각각 아래의 장점과 단점을 가진다.
- 장점 : 불특정 다수를 대상으로 하는 서비스에 적합한 방식이다. 수십만명이 웹 서비스를 사용하더라도 접속유지는 최소한으로 할 수 있기 때문에, 더 많은 유저의 요청을 처리할 수 있다.
- 단점 : 연결을 끊어버리기 때문에, 클라이언트의 이전 상태를 알 수가 없다. 이러한 HTTP의 특징을 stateless라고 하는데, Connectless로 부터 파생되는 특징이라고 할 수 있다. 클라이언트의 이전 상태 정보를 알 수 없게 되면, 웹 서비스를 하는데 당장에 문제가 생긴다. 예컨데, 클라이언트가 과거에 로그인을 성공하더라도 로그 정보를 유지할 수가 없다. HTTP는 cookie를 이용해서 이 문제를 해결하고 있다.
1.5 URI
클라이언트 프로그램(이하 웹 브라우저)은 URI를 이용하여 자원의 위치를 찾는다. URI는 HTTP와는 독립된 다른 체계다. HTTP는 전송 프로토콜이고, URI는 자원의 위치를 알려주기 위한 프로토콜이다. Uniform Resource Identifiers 의 줄임로, World Wide Web 상에서 접근하고자 하는 자원의 위치를 나타내기 위해서 사용한다. 자원은 "문서", "이미지", "동영상", "프로그램", "이메일"등 모든 것이 될 수 있다. 메일을 받을 상대방의 위치를 나타내기 위해서 사용하는 email://yundream@joinc.co.kr, 웹페이지의 위치를 나타내기 위해서 사용하는 http://www.joinc.co.kr/index.php 등이 URI의 예다.
http://www.joinc.co.kr/index.php 를 분석해보자.
- http : 자원에 접근하기 위해서 http 프로토콜을 사용한다.
- www.joinc.co.kr : 자원의 인터넷 상에서의 위치는 www.joinc.co.kr이다. 도메인은 ip 주소로 변환되므로, ip 주소로 서버의 위치를 찾을 수 있다.
- index.php : 요청할 자원의 이름이다.
1.6 Method(메서드)
메서드는 요청의 종류를 서버에게 알려주기 위해서 사용한다. 다음은 요청에 사용할 수 있는 메서드들이다.
- GET : 정보를 요청하기 위해서 사용한다. (SELECT)
- POST : 정보를 밀어넣기 위해서 사용한다. (INSERT)
- PUT : 정보를 업데이트하기 위해서 사용한다. (UPDATE)
- DELETE : 정보를 삭제하기 위해서 사용한다. (DELETE)
- HEAD : (HTTP)헤더 정보만 요청한다. 해당 자원이 존재하는지 혹은 서버에 문제가 없는지를 확인하기 위해서 사용한다.
- OPTIONS : 웹서버가 지원하는 메서드의 종류를 요청한다.
- TRACE : 클라이언트의 요청을 그대로 반환한다. 예컨데 echo 서비스로 서버 상태를 확인하기 위한 목적으로 주로 사용한다.
- GET과 POST만으로도 모든 종류의 요청을 표현할 수 있어서
- 편하게 개발하고 싶어서
- 웹 브라우저로 DELETE, HEAD등을 보내는 form이 없어서 이다.
그렇다. Restful API 서버의 경우에는 GET, POST, DELETE, PUT을 명시적으로 구분한다. 자원의 위치 뿐만 아니라 자원에 할 일 까지 명확히 명시할 수 있기 때문에, Open API 서버를 만들기 위해서 널리 사용한다. 아래는 사용 예다.
- GET api.joinc.co.kr/user/list : 유저 목록을 가져온다.
- POST api.joinc.co.kr/user/create : 유저를 생성한다. 생성에 필요한 유저 정보는 POST 데이터 형식으로 전달할 수 있다.
- PUT api.joinc.co.kr/usr/123 : 유저 ID가 123인 유저의 정보를 업데이트 한다.
- DELETE api.joinc.co.kr/user/123 : 유저 ID가 123인 유저를 삭제한다.
1.7 요청 데이터 포멧
웹 브라우저는 웹 서버에 데이터를 "요청"하는 "클라이언트 프로그램" 이다. 요청은 서버가 인식할 수 있는 약속된 형식(HTTP 형식)을 따라야 한다.
요청 데이터는 "HEADER"와 "BODY"로 구성된다.
헤더에는 요청과 요청 데이터에 대한 메타정보들이 들어있다. 다음은 헤더의 일반적인 모습이다.
1 GET /cgi-bin/http_trace.pl HTTP/1.1\r\n 2 ACCEPT_ENCODING: gzip,deflate,sdch\r\n 3 CONNECTION: keep-alive\r\n 4 ACCEPT: text/html,application/xhtml+xml,application/xml;q=0.9,*/*;q=0.8\r\n 5 ACCEPT_CHARSET: windows-949,utf-8;q=0.7,*;q=0.3\r\n 6 USER_AGENT: Mozilla/5.0 (X11; Linux i686) AppleWebKit/535.1 (KHTML, like Gecko) Chrome/13.0.782.24\r\n 7 ACCEPT_LANGUAGE: ko-KR,ko;q=0.8,en-US;q=0.6,en;q=0.4\rn 8 HOST: www.joinc.co.kr\r\n 9 \r\nHTTP 헤더는 라인피드와 캐리지 리턴(/r/n)을 함께 사용한다. HTTP 헤더를 파싱할 때 주의해야 한다.
- 필수 요소로 요청의 제일 처음에 와야 한다 3개의 필드로 이뤄져 있다.
- 요청 메서드 : GET, PUT, POST, PUSH, OPTIONS 등의 요청 방식이 온다.
- 요청 URI : 요청하는 자원의 위치를 명시한다.
- HTTP 프로토콜 버전 : 웹 브라우저가 사용하는 프로토콜 버전이다. (2013년 6월)현재
1.8 응답 헤더 포멧
응답 헤더포멧이다. 응답 헤더는 서버의 여러 상태 정보를 포함하기 때문에, 꽤 복잡해질 수 있다. wget을 이용하면 헤더 정보를 가져올 수 있다.
# wget -S http://www.test.co.krsdf HTTP/1.1 200 OK\r\n Date: Fri, 08 Jul 2011 00:59:41 GMT\r\n Server: Apache/2.2.4 (Unix) PHP/5.2.0\r\n X-Powered-By: PHP/5.2.0\r\n Expires: Mon, 26 Jul 1997 05:00:00 GMT\r\n Last-Modified: Fri, 08 Jul 2011 00:59:41 GMT\r\n Cache-Control: no-store, no-cache, must-revalidate\r\n Content-Length: 102\r\n Keep-Alive: timeout=15, max=100\r\n Connection: Keep-Alive\r\n Content-Type: text/html\r\n \r\n
- wget으로 헤더 정보를 출력했다.
- 프로토콜과 응답코드 : 반드시 첫줄에 와야 한다. 3개의 필드로 구성돼 있다.
- HTTP/1.1 : 응답 프로토콜과 버전
- 200 : 응답 코드
- OK : 응답 메시지. Not Found, Internal Server Error 등의 메시지다.
- 날짜
- 서버 프로그램및 스크립트 정보.
- 응답헤더에는 다양한 정보를 추가할 수가 있다. 어떤 정보를 추가할지는 사실 개발자 마음이다. HTTP 기반의 서버/클라이언트 제품을 만든다면, 헤더에 애플리케이션 정보를 추가해서 사용하면 된다.
- 컨텐츠의 마지막 수정일
- 캐쉬 제어 방식.
- 컨텐츠 길이.
- Keep Alive기능 설정이다. keep alive는 클라이언트측에 연결을 유지하라는 신호를 보내기 위해서 사용한다. 그러면 클라이언트는 최대 timeout에 지정된 시간동안 연결을 유지한다 . 이 시간동안 클라이언트는 이미 맺어진 연결로 요청을 계속 보낼 수 있다 . Keep Alive는 따로 자세히 설명한다.
- Content-Type. 응답에 실어 보내는 컨텐츠가 HTML 문서인지, 이미지인지, CSS, JavaScript›인지 혹은 다른 애플리케이션 형태인지를 알려준다. 웹 애플리케이션들은 Content-Type에 따라서 Body의 데이터를 어떻게 읽을지를 결정한다. 따라서 전송 데이터에 맞는 content-type를 명시해야 한다.
1.9 응답코드
서버는 응답코드로 서버의 상태를 알려준다. 3자리의 숫자로 이루어져 있다. 주요 응답코드를 정리했다. 응답코드는 응답헤더의 첫번째 줄에 위치하다.
- HTTP/1.1 200 OK\r\n
- HTTP/1.1 404 Not Found\r\n
- HTTP/1.1 500 Internal error\r\n
1.9.1 1xx 조건부 응답
이건 사용해 본적이 없다. 없을 뿐만 아니라 문서를 읽어도 도대체 무슨내용인지 알 수 없어서 공백으로 뒀다. 아시는 분은 코멘트 부탁.
HTTP 요청은 수신 됐고, 다음 처리를 계속해야함을 의미합니다.
1.9.2 2xx 성공
서버가 요청을 성공적으로 처리했음을 의미한다.
| 코드번호 | 설명 | 비고 |
| 200 | 성공 | 서버가 요청을 제대로 처리했다. |
| 201 | 생성됨 | 요청이 성공했으며, 새로운 리소스를 만들었다. |
| 202 | 허용됨 | 요청을 받았으나, 아직 처리하지는 못했다. |
| 204 | 컨텐츠 없음 | 요청을 처리했지만, 컨텐츠를 제공하지 않는다. |
| 205 | 컨텐츠 재 설정 | 요청을 처리했지만, 컨텐츠를 표시하지 않는다. 그리고 문서를 재 설정할 것을 요구한다. |
| 206 | 일부 성공 | 요청의 일부만 성공적으로 처리 |
| 207 | 다중상태 |
1.9.3 3xx 리다이렉션
때때로 요청을 완료하기 위해서, 다른 페이지로 보내야 할 때가 있다. 예컨데, 로그인을 성공하고 나서 대문 페이지로 보낸다거나, 다운로드 페이지로 보내는 등의 용도로 사용할 수 있다.
| 코드번호 | 설명 | 비고 |
| 300 | 여러 선택 항목 | |
| 301 | 영구이동 | 요청한 페이지가 다른 위치로 영구이동 했다. |
| 302 | 임시이동 | 요청한 페이지가 다른 위치로 임시이동 했다. 요청자는 여전히 현재 페이지를 요청해야 한다. |
| 303 | 기타위치 보기 | 요청자가 다른 위치에 별도의 GET 요청을 하여 응답을 검색할 경우 |
| 304 | 수정되지 않음 | 마지막 요청 이후 요청한 페이지가 수정되지 않았다. if-Modified-Sine 헤더에 지정된 날짜/시간 이래로 지정된 문서가 변경된 사실이 없는 경우 이 code로 응답한다. |
| 305 | 프록시 사용 | 요청자는 프록시를 사용하여 요청한 페이지만 접근할 수 있다. |
1.9.4 4xx 요청 오류
클라이언트 요청에 오류가 있음을 의미한다.
| 코드번호 | 설명 | 비고 |
| 400 | 잘못된 요청 | 주로 헤더 포멧이 HTTP 규약에 맞지 않을 경우 |
| 401 | 권한 없음 | 인증을 필요로 하는 요청이다. Basic access authentication에 사용한다. |
| 403 | 금지 | 서버가 요청을 거부하고 있다. |
| 404 | 찾을 수 없음 | 요청한 자원이 서버에 존재하지 않는다. |
| 405 | 허용하지 않는 방법 | 요청에 지정한 방법을 사용할 수 없다. |
| 406 | 허용되지 않음 | 요청한 페이지를 콘텐츠 특성 때문에 응답할 수 없다. |
| 408 | 요청시간 초과 | 서버의 요청대기가 시간을 초과 |
| 410 | 사라짐 | 요청한 자원이 삭제되었음. 404와 비슷하지만, 410은 과거에 있었으나 지금 없는 자원이다. 예컨데, 게시판에서 삭제한 포스트에 접근하는 경우 |
| 411 | 길이필요 | 유효한 컨텐츠 길이를 명시해야 한다. |
1.10 Keep Alive
HTTP 1.1 부터는 keep-alive 기능을 지원한다.
HTTP는 하나의 연결에 하나의 요청을 하는 것을 기준으로 설계가 됐다. 요즘 웹 서비스의 경우 간단한 페이지라고 해도 수십개의 데이터 - 이미지, 문서, css, javascript - 등이 있기 마련인데, HTTP의 원래 규격대로라면 웹페이지를 하나 표시하기 위해서 연결을 맺고 끝는 과정을 수십번을 반복해야 한다. 당연히 비효율적일 수 밖에 없다. 연결을 맺고 끝는 것은 TCP 통신 과정에서 가장 많은 비용이 소비되는 작업이기 때문이다.
예를들어 HTML로 표현된 문서를 다운로드 받는다고 가정해 보자. 이 문서에는 20여개 정도의 이미지, css, javascript 파일이 있다. Keep alive를 지원하지 않을 경우 다음과 같은 과정을 거친다.
- 웹 서버에 연결한다.
- HTML 문서를 다운로드 한다.
- 웹 서버 연결을 끊는다.
- HTML 문서의 image, css, javascript 링크들을 읽어서 다운로드해야할 경로를 저장한다.
- 웹 서버에 연결한다.
- 첫번째 이미지를 다운로드
- 연결을 끊는다.
- 웹 서버에 연결한다.
- 두번째 이미지를 다운로드
- 연결을 끊는다.
- 모든 링크를 다운로드 할 때까지 반복한다.
- 웹 서버에 연결한다.
- HTML 문서를 다운로드 한다.
- Image, css, javascript 들을 다운로드 한다.
- 모든 문서를 다운로드 받았다면 연결을 끊는다.
1.10.1 Keep alive 설정
Keep-alive는 HTTP/1.1 부터 사용할 수 있다. (2013년 6월 현재)모든 웹서버와 브라우저는 HTTP/1.1을 지원한다고 가정해도 무방하다. 아래와 같은 과정을 거쳐서 keep alive를 설정을 한다.
- 웹 브라우저는 요청 헤더에 keep-alive 방식의 연결을 할 것을 명시한다. chrom웹 브라우저로 www.joinc.co.kr로의 연결 요청을 캡춰했다.
Accept:text/html,application/xhtml+xml,application/xml;q=0.9,*/*;q=0.8 Accept-Charset:windows-949,utf-8;q=0.7,*;q=0.3 Accept-Encoding:gzip,deflate,sdch Accept-Language:ko-KR,ko;q=0.8,en-US;q=0.6,en;q=0.4 Connection:keep-alive Host:www.joinc.co.kr Referer:http://www.joinc.co.kr/ User-Agent:Mozilla/5.0 (X11; Linux x86_64) AppleWebKit/537.31 (KHTML, like Gecko) Chrome/26.0.1410.63 Safari/537.31
- 웹 서버의 설정이 kepp-alive 방식을 지원하도록 설정돼 있다면, 응답 헤더에 keep-alive 정보를 실어 보낸다. www.joinc.co.kr 서버의 응답 헤더의 일부분이다.
Connection:Keep-Alive Keep-Alive:timeout=5, max=100 Content-Encoding:gzip Content-Length:5933 Content-Type:text/html Vary:Accept-Encoding
- connection:Keep-Alive : 연결을 keep-alive 상태로 유지한다.
- Keep-Alive:timeout=5, max=100 : 하나의 연결당 5초동안 유지한다. Keep-alive 연결은 최대 100개까지 허용한다. keep-alive는 하나의 연결로 여러 요청을 처리하기 때문에 효율적이긴 하지만, 연결이 그만큼 길어지기 때문에 동시간대 연결이 늘어난다. 운영체제에 있어서 연결은 "유한한 자원"이다. 연결을 다 써버리면, 서버는 더 이상 연결을 받을 수 없게 된다. Max 값을 이용해서 keep-alive 연결을 제한하는 이유다.
1.11 세션 관리
HTTP를 기반으로 하는 웹 서비스는 connectless방식으로 이전의 상태정보를 유지할 수 없다. 결국 클라이언트의 상태정보를 정보조각 형태로 서버와 클라이언트(웹 브라우저)에 남기는 방식으로 문제를 해결한다. 이 정보조각을 cookie(이하 쿠키)라고 한다. 서버는 cookie를 이용해서 세션정보를 관리한다.
세션과 cookie 관계를 정리하자면
- 서버는 클라이언트와 cookie를 주고 받는 것으로 상태를 확인할 수 있다.
- ex) 클라이언트가 로그인을 한 상태인지
- 서버는 cookie를 키로하는 값을 데이터베이스에 저장하는 방식으로 "세션"을 유지한다.
- ex) 로그인한 클라이언트가 "물건 - A"를 구매했다면, 클라이언트의 cookie id를 key로 데이터베이스에 구매정보를 update 한다.
- ex) 로그인한 클라이언트가 "물건 - A"를 구매했다면, 클라이언트의 cookie id를 key로 데이터베이스에 구매정보를 update 한다.
2 디버깅 및 성능 측정
HTTP를 기반으로 하는 웹 서버를 디버깅하는 방법에 대해서 알아본다. 모든 디버깅이 그렇듯이, 핵심은 헤더의 확인 특히 응답코드를 확인하는데 있다.
2.1 디버깅은 리눅스로
설명할 대부분의 툴들은 공개소프트웨어로 리눅스에서 테스트했다. 아마도 윈도우에서도 비슷한 툴들을 사용할 수 있을 테지만, (거의 대부분의 툴이 기본설치되는)리눅스 환경 만큼 편하지는 않을 것이다.
2.2 telnet 으로 디버깅
Telnet는 HTTP을 포함한 모든 네트워크 프로그램 테스트에 사용할 수 있는 도구다. Telnet는 원시도구인 만큼 복잡한 디버깅은 힘들지만, 초기에 빠르게 디버깅 정보를 획득할 때 유용하게 사용할 수 있다. Telnet으로 디버깅 할 수 있는 정보는 다음과 같다.
웹 서버가 올라왔는지 확인한다. 웹 서버포트(보통 80번 포트)에 대해서 테스트해보자.
# telnet www.joinc.co.kr 80 Trying xxx.xxx.xxx telnet: Unable to connect to remote host: Connection refusedConnection refuse가 떨어지면, 서비스 포트가 열려있지 않다는 것을 의미한다.
입력 프롬프트가 떨어지면, 연결이 됐다는 것을 의미한다.
# telnet www.joinc.co.kr 80 Trying 1.226.82.91... Connected to www.joinc.co.kr. Escape character is '^]'.이 상태에서 HTTP 명세대로 요청을 보내면 응답을 받을 수 있다. www.joinc.co.kr에 index.html을 요청한 예다.
$ telnet www.joinc.co.kr 80 Trying 1.226.82.91... Connected to www.joinc.co.kr. Escape character is '^]'. GET /index.html HTTP/1.1 HOST: www.joinc.co.kr HTTP/1.1 200 OK Date: Sun, 16 Jun 2013 02:28:28 GMT Server: Apache/2.2.14 (Ubuntu) Last-Modified: Fri, 22 Jun 2012 06:58:22 GMT ETag: "c43e-76-4c30a286a7f80" Accept-Ranges: bytes Content-Length: 118 Vary: Accept-Encoding Content-Type: text/html <head> <meta http-equiv="refresh" content="0;URL=http://www.joinc.co.kr/modules/moniwiki/wiki.php/FrontPage"> </head> Connection closed by foreign host.
telnet으로 연결 했는데, timeout이 떨어질 때가 있다. 문제의 원인은 보통 둘 중 하나다.
- 방화벽으로 막혀있거나
- 서버에 문제가 생겼다.
2.3 chrome 으로 디버깅
telnet를 이용해서 웹 서버 상태를 빠르게 파악한뒤에 더 자세한 정보가 필요하다면 chrome의 개발자도구를 이용하면 된다. chrome에서 F12를 누르면, 창 하단에 디버깅 창이 뜬다. Chrom의 개발자 도구[4]는 웹 프로그램 개발자라면 반드시 익혀야 할 툴 중 하나다.

2.3.1 Elements
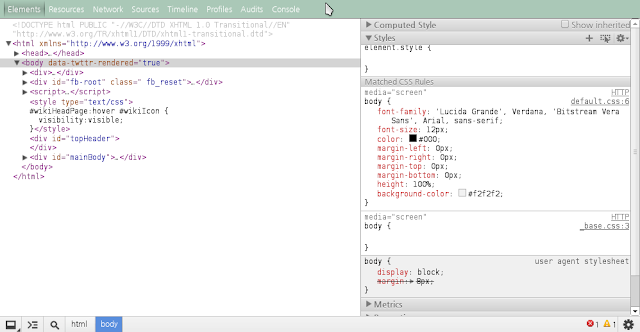
HTML 문서의 DOM element를 보여준다. 보여줄 뿐만 아니라 element의 값을 수정하고, 그 결과를 브라우저 상에서 직접 확인할 수 있다. 예컨데, 웹 페이지의 디자인을 바꾸기 위해서 코드를 변경하고 브라우저로 확인하는 노가다를 할 필요가 없다. Element 창에서 실시간으로 수정하고 변화된 모습을 확인할 수 있다.
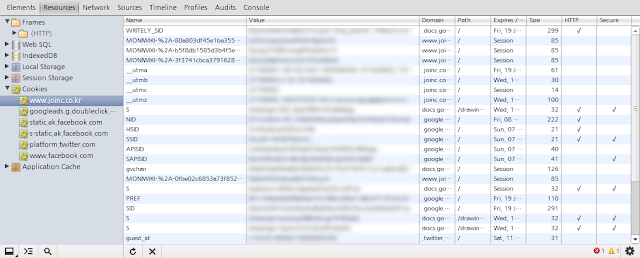
2.3.2 Resources
Cookie, Local Storage 등의 정보를 확인할 수 있다. 개인적으로 Cookie 창을 주로 사용한다.
2.3.3 Network
요청과 응답에 걸린 시간을 측정할 수 있다. 이 정보를 토대로 대략적인 웹페이지 전송시간과 병목구간을 찾아낼 수 있다.
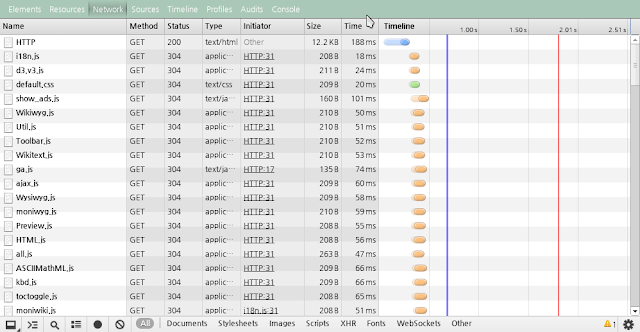
HTTP 프로토콜 수준에서 디버깅할 때 유용한 기능이다. HTTP 요청 헤더와 응답 헤더, Body 정보를 확인할 수 있다.

2.3.4 Profiles
메모리 사용정보를 실시간으로 확인할 수 있다. 하단의 Record버튼을 누르면 메모리 정보를 수집하기 시작한다.
2.3.5 Audits
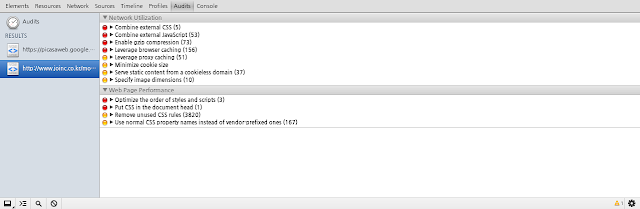
페이지에 대한 감사를 수행한다. 페이지 최적화를 위한 정보를 얻기 위해서 사용한다. 위 스샷은 joinc.co.kr에 대한 감사 결과다. 음.. 최적화를 수행해야 할 것 같다.
2.3.6 Console
자바스크립트 개발자에게 반드시 있어야 하는 툴이지 싶다. 강력한 만큼 기능이 많다. 자세한 내용은 http://ohgyun.com/334 를 참고하자.
2.3.7 curl 로 디버깅
curl은 서버로 데이터를 전송하기 위해서 사용하는 툴로 DICT, FILE, FTP, FTPS, GOPHER, HTTP, HTTPS, IMAP, LDAP, LDAPS, POP3, POP3S, RTMP, RTSP, SCP, SFTP, SMTP, SMTPS, TELNET, TFTP등 주요 인터넷 서비스 프로토콜들을 지원한다.
curl의 장점은 상호작용없이 CLI를 통해서 작업을 할 수 있다는데 있다. 직접 웹 서버를 테스트하거나 웹 서버를 관리하는 스크립트를 작성하기 위해서 널리 사용한다.
curl 사용방법은 curl 사용 tip문서를 참고하자.
2.3.8 wget 으로 디버깅
또 하나의 강력한 툴이다. wget은 웹에 있는 문서나 파일을 다운로드 하기 위한 목적으로 주로 사용하는데, curl과 마찬가지로 CLI 기반이라서, 자동화 툴을 개발하기 위한 목적으로 널리 사용한다.
wget과 관련된 자세한 내용은 wget man page문서를 참고한다. wget으로 할 수 있는 일들은 다음과 같다.
-d 옵션을 이용하면, 서버와 클라이언트 간에 일어나는 요청/응답 과정과 주고 받는 데이터를 확인할 수 있다.
- -S 옵션을 이용해서 응답 헤더 정보를 읽을 수 있다.
# wget -S http://www.joinc.co.kr --2013-06-19 15:05:03-- http://www.joinc.co.kr/ Resolving www.joinc.co.kr (www.joinc.co.kr)... 1.226.82.91 Connecting to www.joinc.co.kr (www.joinc.co.kr)|1.226.82.91|:80... connected. HTTP request sent, awaiting response... HTTP/1.1 200 OK Date: Wed, 19 Jun 2013 15:01:21 GMT Server: Apache/2.2.14 (Ubuntu) Last-Modified: Fri, 22 Jun 2012 06:58:22 GMT ETag: "c43e-76-4c30a286a7f80" Accept-Ranges: bytes Content-Length: 118 Vary: Accept-Encoding Keep-Alive: timeout=5, max=100 Connection: Keep-Alive Content-Type: text/html
2.3.9 scapy를 이용한 디버깅
3 HTTP 응용 소프트웨어
3.1 웹 서버들
| 프로그램 이름 | 벤더 | 웹 사이트 호스트 수 | 점유율 |
| Apache | Apache | 359,441,468 | 53.42 % |
| IIS | Microsoft | 112,303,412 | 16.69 % |
| nginx | NGINX. Inc | 104,411,087 | 15.52 % |
| GWS | 23,029,260 | 3.42 % |
자세한 정보는 http://news.netcraft.com/archives/2013/03/01/march-2013-web-server-survey.html 를 참고하자. Apache가 짱이고, nginx가 떠오르는 형국이다.
3.2 웹 브라우저들
웹 브라우저의 대략 적인 발표시기.
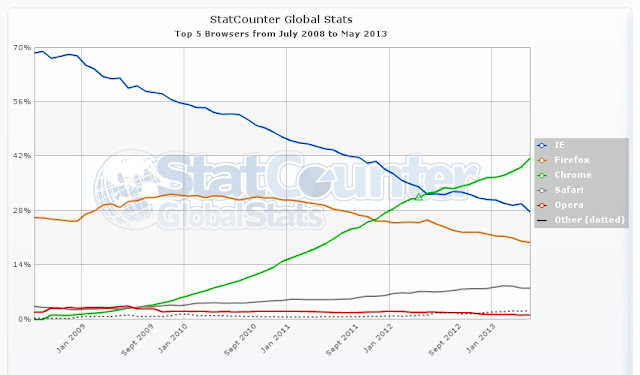
- 1990년 : Tim Berners-Lee가 첫번째 브라우저를 개발하다.
- 1993년 : Mosaic 웹브라우저 개발. 대중적으로 사용된 첫번째 웹브라우저다. Mosic은 나중에 Netscape가 된다.
- 1996년 : 인터넷 익스플로어 개발. 시작은 미약했으나 MS 운영체제의 파워에 힘입어 1996년 82%의 시장점유율을 기록하기도 했다. 그후 계속 점유율이 떨어져 지금은 20%정도에 머무르고 있다.
- 1996년 : Opera.
- 2002년 : Firefox
- 2004년 : Safari
- 2009년 : Chrome의 성장은 눈부시다고 할 수 있다. 약 4년이지난 2013년 현재, 32%의 점유율로 가장 많이 사용하는 브라우저가 됐다.
4 HTTP 응용
4.1 REST
HTTP의 메서드를 다시 한번 살펴보자.
- GET : 정보를 요청하기 위해서 사용한다. (SELECT)
- POST : 정보를 밀어넣기 위해서 사용한다. (INSERT)
- PUT : 정보를 업데이트하기 위해서 사용한다. (UPDATE)
- DELETE : 정보를 삭제하기 위해서 사용한다. (DELETE)
이렇게 HTTP가 CRUD 요소를 모두 가지고 있다는 것에 착안, 웹 상에서 데이터를 처기하기 위한 아키텍처를 제안한게 바로 REST다. REST는 추가적인 레이어나 세션 관리등을 추가하지 않고도 HTTP 프로토콜만을 이용해서 데이터를 전송할 수 있다는 장점이 있다. 게다가 이미 전세계적으로 깔려있는 HTTP 기반의 소프트웨어 인프라를 그대로 활용할 수 있다는 장점도 가지고 있다.
이렇게 REST 아키텍처를 개발하는 서비스를 RESTful 서비스라고 한다.
REST의 특징은 다음과 같다. (HTTP 기반이라서 HTTP의 특징과 장점을 그대로 가진다.)
- HTTP만으로 데이터를 전송하고 처리할 수 있다.
- Stateless
- URI를 이용해서 자원에 접근한다. URI의 가장 중요한 요소는 자원(Resource)다. 이러한 접근 방식의 특징으로 ROA(리소스 기반 아키텍처)라고 한다. ROA와 대비되는 개념으로 SOA(소프트웨어 기반 아키텍처)가 있다.
- 단순하며 사용하기 쉽다. REST는 HTTP외에 다른 프로토콜을 필요로 하지 않는다. HTTP를 이해하고 있다면, 몇 분만의 설명으로 아키텍처를 이해할 수 있다. 데이터를 주고 받는 모든 과정과 데이터 포멧 역시 사람이 해석할 수 있을 정도로 직관적이다.
REST와 관련해서는 비슷한 목적의 SOAP도 살펴볼 필요가 있겠다. REST는 REST에 대해서에서 따로 정리하고 있다.
5 HTTPS
HTTP는 기본적으로 평문 데이터 전송을 원칙으로 하기 때문에 개인의 프라이버시가 오가는 서비스들(전자상거래, 전자메일, 사내문서)에 사용하기 힘들다. HTTPS는 SSL 레이어위에 HTTP를 통과 시키는 방식이다. 즉 평문의 HTTP 문서는 SSL 레이어를 통과하면서 암호화 돼서 목적지에 도착하고, 목적지에서는 SSL 레이어를 통과하면서 복호화 돼서 웹 브라우저에 전달된다.
간혹 HTTPS를 하나의 프로토콜로 인식하기도 하는데, HTTP와 SSL은 전혀 다른 계층의 프로토콜콜의 조합이다. HTTPS over SSL로 보는게 좀더 정확한 시각이다. 거의 모든 웹 서버와 웹 브라우저와 HTTP 기반의 툴들 - wget, curl, ab 기타등등 - 이 SSL을 지원한다.
5.1 HTTP와 다른 점
- HTTPS URL은 "https://"로 시작한다. 기본 포트번호는 443이다. HTTP URL은 "http://"로 시작한다. 기본 포트번호는 80이다.
- HTTP는 평문 데이터를 기반으로 하기 때문에, 유저정보와 같은 민감한 정보가 인터넷 상에 그대로 노출된다. 이 정보는 수집되거나 변조될 수 있다. HTTPS는 이러한 공격을 견딜 수 있도록 설계돼 있다.
- HTTPS는 인증서를 이용해서, 접속 사이트를 신뢰할 수 있는지 평가할 수 있다.
- 일반적으로 HTTPS는 HTTP에 비해서 (매우 많이)느리다. 많은 양의 데이터를 처리할 경우 성능의 차이를 체감할 수 있다. 많은 웹 사이트들이 민감한 정보를 다루는 페이지(로그인 혹은 유저정보) 페이지를 HTTPS로 전송하고, 기타 페이지는 HTTP로 전송하는 방법을 사용한다. 하드웨어 SSL 가속기를 이용해서 암/복호화 성능을 높이는 방법을 사용하기도 한다.
6 HTTP 응답 헤더 예제
6.1 200 OK
요청을 성공적으로 처리했을 때, 웹 서버는 200 코드를 반환한다.
HTTP/1.1 200 OK Content-Type: text/html;charset=utf-8 Content-Length: 0 X-Xss-Protection: 1; mode=block X-Content-Type-Options: nosniff X-Frame-Options: SAMEORIGIN Server: WEBrick/1.3.1 (Ruby/1.9.3/2012-04-20) Date: Tue, 17 Sep 2013 12:46:12 GMT Connection: Keep-Alive
6.2 URL Redirect
URL Redirect를 위해서 서버는 301 코드를 반환한다. Location에 리다이렉트할 URL을 명시한다. 301 코드를 받은 클라이언트는 Location 주소로 접속을 시도한다.
HTTP/1.1 301 Moved Permanently Content-Type: text/html;charset=utf-8 Location: http://192.168.56.101/ok Content-Length: 0 X-Xss-Protection: 1; mode=block X-Content-Type-Options: nosniff X-Frame-Options: SAMEORIGIN Server: WEBrick/1.3.1 (Ruby/1.9.3/2012-04-20) Date: Tue, 17 Sep 2013 12:36:01 GMT Connection: Keep-Alive
7 보안
7.1 인증
7.1.1 Basic access authentication
HTTP 영역에서 이루어지는 인증이다. HTTP 영역이기 때문에 인증은 웹 서버 차원에서 이루어진다. 매 요청마다 HTTP 헤더에 아이디와 패스워드를 실어 보내면, 서버에서 아이디와 패스워드를 확인한다.
인증 프로세스는 다음과 같다.
- HTTP 요청을 보낸다.
- 웹 서버는 401 Authorization Required를 응답한다. 인증이 필요하니, 인증 정보를 보내란 이야기가 되겠다.
- 브라우저는 아이디 패스워드를 입력할 수 있는 인증 창을 띄운다.
- 입력한 아이디/패스워드는 HTTP 헤더에 담아서 웹 서버로 보낸다.
- 웹 서버는 아이디와 패스워드를 확인한다. 일치하는 아이디/패스워드가 있으면 요청을 처리한다.
간단한 만큼, 높은 보안성을 기대하지 않는게 좋다. BA는 아이디와 패스워드를 base64 인코딩해서 전송한다. 암호화 혹은 해쉬등의 기술을 사용하지 않는다. 따라서 아이디/패스워드를 보호해야 한다면 HTTPS를 이용해야만 한다.
매 요청마다 아이디와 패스워드를 보내는 방식이기 때문에, 클라이언트 프로그램은 처음 입력한 아이디와 패스워드를 저장하기 캐쉬를 가지고 있어야 한다. 브라우저마다 캐쉬를 유지하는 시간에 차이가 있다. MS IE는 15분으로 설정돼 있다. 로그아웃기능이 없기 때문에 개인 PC가 아니라면 자리를 뜨기전에 브라우저 캐쉬를 비워줘야 한다.
다음은 서버 사이드 프로토콜 형식이다.
HTTP/1.1 401 Authorization Required Date: Wed, 02 Apr 2014 08:23:28 GMT Server: Apache/2.2.14 (Ubuntu) WWW-Authenticate: Basic realm="sample" Vary: Accept-Encoding Content-Length: 484 Content-Type: text/html; charset=iso-8859-1
아래는 클라이언트측 프로토콜이다.
GET / HTTP/1.1 HOST: sample.joinc.co.kr Authorization: Basic QWxhZGRpbjpvcGVuIHNlc2FtZQ==
아이디와 패스워드는 "아이디:패스워드"로 base64 인코딩 된다. 아이디가 yundream, 패스워드가 1111 일 경우 아래와 같이 인코딩하면 된다.
# echo -n "yundream:1111" | openssl base64 eXVuZHJlYW06MTExMQ== # echo -n "yundream:1111" | python -m base64 -e eXVuZHJlYW06MTExMQ==
7.1.2 Digest access authentication
나중에 정리..
8 참고 문서
- http://ko.wikipedia.org/wiki/HTTP_상태_코드
- http://blog.naver.com/PostView.nhn?blogId=sjbae75&logNo=40072576305
- http://en.wikipedia.org/wiki/HTTP_cookie
- SOAP 기반 웹서비스와 RESTful 웹서비스 기술 비교
- 웹 브라우저 점유율 : http://gs.statcounter.com/
- 웹 서버 시장 자료 : http://news.netcraft.com/archives/category/web-server-survey/
- http://en.wikipedia.org/wiki/HTTP_Secure
- 캐쉬 관련 헤더
'웹' 카테고리의 다른 글
| HTML 특수문자코드표 (0) | 2016.04.25 |
|---|---|
| CGI와 PHP 관계 (0) | 2015.10.16 |
| MySQL join (0) | 2015.08.24 |
| [HTML] favicon 생성 (0) | 2015.07.29 |
| [CSS] address 태그 (0) | 2015.07.28 |

























